字符编码
http://nozer0.github.io/zh/technology/system/character-encoding/上一次,我们了解了计算机中的数字,这次我们来看一下计算机中的字符。
介绍
本文中有一些术语,例如‘字符集’,‘字符编码’,‘区位码’和‘码点’,从下面的图示中,我们可以先了解总体的概念,在后面会涉及简单的解释。
CharSet Computer
+-----------+ Encoding
| a, b, ... | encode +-----------------+
| | | | | ----------> | 0x61, 0x62, ... |
code point -->| 97 98 ... | +-----------------+
+-----------+
首先,我们来看一下最重要的两个概念,字符集(character set)和编码(Encoding)。通常当人们谈论这两者时,指的是同一概念,但有时候,也有各自不同的意义。
-
字符集, ‘Character set’,或者‘CharSet’,是字符的集合,例如某个语言用到所有的字符。在字符集中代表字符的数值称为该字符的码点(code point)。
-
字符编码,‘character encoding system’, 是将字符集映射为类似点阵,数字等序列的方案。不仅仅在计算科学领域,在日常生活中我们也能时常遇到。例如,字典,就包含了一种或几种编码方式来帮助我们快速找到字符,或者当我们寄信时,需要注明收件人的邮政编码,这就是居住地址的一种编码方式。
在大多数情况下,这两者在信息科学中概念相同,例如‘ASCII’,‘ISO8859’;但有时也不同,例如,‘EUC-CN’是字符集‘GB2312’的一种编码。
SBCS
单字节字符系统(Single-Byte Character System),我们可以从名称知道该系统的字符可以只用7或8比特表示,换句换说,系统包含最多128或256个字符。
我们将接触其中的三种,‘ASCII’和‘ISO 8859’,都是世界上最流行的编码系统,还有专门用于日文的‘JIS X 0201’。
ASCII
美国信息交换标准代码(American Standard Code for Information Interchange),又称为 ‘ISO646-US’ 或IBM命名的 ‘cp367’。对大多数人来说,这应该是最早接触的一种编码。
ASCII基于英文字母表,包含96个可打印字符(26个字母,数字0~9,基础标点符号和空格),32个控制码,一共128个字符,可用7个比特表示。对英语国家的人来说,只需要一个字节就足够代表近乎所有字符,而且还有一个比特可用来做奇偶校验,简单小巧,不是吗?
完整ASCII表格。
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL (Null character) | DLE (Data Link Escape) | SP | 0 | @ | P | ` | p |
| 1 | SOH (Start of Header) | DC1 (Device Control 1) | ! | 1 | A | Q | a | q |
| 2 | STX (Start of Text) | DC2 (Device Control 2) | ” | 2 | B | R | b | r |
| 3 | ETX (End of Text) | DC3 (Device Control 3) | # | 3 | C | S | c | s |
| 4 | EOT (End of Transmission) | DC4 (Device Control 4) | $ | 4 | D | T | d | t |
| 5 | ENQ (Enquiry) | NAK (Negative Acknowledgment) | % | 5 | E | U | e | u |
| 6 | ACK (Acknowledgment) | SYN (Synchronous idle) | & | 6 | F | V | f | v |
| 7 | BEL (Bell) | ETB (End of Transmission Block) | ’ | 7 | G | W | g | w |
| 8 | BS (Backspace, ‘\b’) | CAN (Cancel) | ( | 8 | H | X | h | x |
| 9 | HT (Horizontal Tab, ‘\t’) | EM (End of Medium) | ) | 9 | I | Y | i | y |
| A | LF (Line feed, ‘\n’) | SUB (Substitute) | * | : | J | Z | j | z |
| B | VT (Vertical Tab, ‘\v’) | ESC (Escape) | + | ; | K | [ | k | { |
| C | FF (Form feed, ‘\f’) | FS (File Separator) | , | < | L | \ | l | | |
| D | CR (Carriage return, ‘\r’) | GS (Group Separator) | - | = | M | ] | m | } |
| E | SO (Shift Out) | RS (Record Separator) | . | > | N | ^ | n | ~ |
| F | SI (Shift In) | US (Unit Separator) | / | ? | O | _ | o | DEL |
ISO/IEC 8859
对US来说,ASCII已能满足要求,但是对拉丁语系的其他国家来说,则需要表示更多的符号,因此定义了基于ASCII的8比特编码系统。对不同的区域有不同的变体,如 ‘ISO-8859-1’ 是用于西欧的,‘ISO-8859-2’ 是相对于中欧的。
所有‘ISO 8859’变体起始的128个字符都和ASCII系统相同,这被称为ASCII兼容字符集。事实上,‘ISO 8859’只定义了字节‘0xA0~0xFF’所代表的字符,而‘ISO 6429’定义了C0和C1控制字符(0x00~0x1F,0x80~0x9F),更准确的说,ISO-8850 = ASCII + ISO 6429 + ISO 8859,注意连字符‘-’。
JIS X 0201
这是早期日本设定的单字节字符集,与ASCII不同,‘0x5c’表示的是‘¥’,而不是‘\’,这就是为什么我们经常在日文系统中能看到这样的路径‘C:¥windows¥system’,同样的,‘0x7E’也从‘~’变为‘‾’。并且字节‘0xA1~0xDF’被用来表示半角片假名。
MBCS
多字节字符系统(Multi-Byte Character System),相对于主要用于拉丁语系国家的SBCS来说,MBCS主要是为拥有更多字符需要表示的其他国家服务,例如中国或日本。显然,1个字节不足以表示那么多的字符。
ISO/IEC 2022
ISO 2022既不是字符集,也不是字符编码,而是一种标准或者说代码扩展技术,使得单个编码系统可以对应于多个不同的字符集。该标准指定了用1个字节(7比特)来表示94个可打印字符,为了和ASCII统一,使用了‘0x21~0x7E’的字节范围;2个字节,可以表示94行 x 94列 = 8836个字符,对大多数语言来说,已经足够;特殊的,则使用3个字节,94个不同平面,共830584个字符。
并且,ISO 2022还规定了字符码到显示字符的2层映射,一共指定了4个工作集合,从G0到G3,首先需要检查使用的是哪个工作集合,然后才能根据字节的数值知道所代表的正确字符。下表是默认的情况。
| 集合 | 范围 | 名称 |
|---|---|---|
| CL | 0x00~0x1F | 整表靠左边的控制字符,默认作为C0 |
| GL | 0x20~0x7F | 整表靠左边的图形字符,默认作为G0 |
| CR | 0x80~0x9F | 默认作为C1 |
| GR | 0xA0~0xFF | 默认作为G1 |
此外,ISO 2022还使用‘转义序列’来指示之后字节所在的工作集合。
| 代码 | Hex | 缩写 | 名称 | 效果 |
|---|---|---|---|---|
| SI | 0F | LS0 | Shift In / Locking shift zero | GL开始作为G0编码 |
| SO | 0E | LS1 | Shift Out / Locking shift one | GL开始作为G1编码 |
| ESC n | 1B 6E | LS2 | Locking shift two | GL开始作为G2编码 |
| ESC o | 1B 6F | LS3 | Locking shift three | GL开始作为G3编码 |
| ESC N | 8E/1B 4E | SS2 | Single shift two | 只是下一个字符GL作为G2编码 |
| ESC O | 8F/1B 4F | SS3 | Single shift three | 只是下一个字符GL作为G3编码 |
| ESC ~ | 1B 7E | LS1R | Locking shift one right | GR开始作为G1编码 |
| ESC } | 1B 7D | LS2R | Locking shift two right | GR开始作为G2编码 |
| ESC | | 1B 7C | LS3R | Locking shift three right | GR开始作为G3编码 |
| ESC ! | 1B 21 | CZD | C0-designate | 使用C0控制符 |
| ESC “ | 1B 22 | C1D | C1-designate | 使用C1控制符 |
| ESC % | 1B 25 | DOCS | Designate other coding system | 8比特编码;使用ESC % @重置回ISO 2022 |
| ESC % / | 1B 25 2F | DOCS | Designate other coding system | 8比特编码;无法重置 |
| ESC ( | 1B 28 | GZD4 | G0-designate 94-set | 94字符集用于G0 |
| ESC ( B | 1B 28 42 | 切换至ASCII | ||
| ESC ( I/J | 1B 28 49/4A | 切换至JIX X 0201 | ||
| ESC ) | 1B 29 | G1D4 | G1-designate 94-set | 94字符集用于G1 |
| ESC * | 1B 2A | G2D4 | G2-designate 94-set | 94字符集用于G2 |
| ESC + | 1B 2B | G3D4 | G3-designate 94-set | 94字符集用于G3 |
| ESC - | 1B 2D | G1D6 | G1-designate 96-set | 96字符集用于G1 |
| ESC . | 1B 2E | G2D6 | G2-designate 96-set | 96字符集用于G2 |
| ESC . A | 1B 2E 41 | 切换至ISO 8859-1 | ||
| ESC . F | 1B 2E 46 | 切换至ISO 8859-7 | ||
| ESC / | 1B 2F | G3D6 | G3-designate 96-set | 96字符集用于G3 |
| ESC $ ( | 1B 24 28 | GZDM4 | G0-designate multibyte 94-set | 94^n字符集用于G0 |
| ESC $ ( C | 1B 24 44 | 切换至KS X 1001 | ||
| ESC $ ( D | 1B 24 44 | 切换至JIS X 0212 | ||
| ESC $ ( O..Q | 1B 24 4F..51 | 切换至JIS X 0213 | ||
| ESC $ ) | 1B 24 29 | G1DM4 | G1-designate multibyte 94-set | 94^n字符集用于G1 |
| ESC $ ) A | 1B 24 29 41 | 切换至GB 2312 | ||
| ESC $ ) C | 1B 24 29 43 | 切换至KS X 1001 | ||
| ESC $ * | 1B 24 2A | G2DM4 | G2-designate multibyte 94-set | 94^n字符集用于G2 |
| ESC $ + | 1B 24 2B | G3DM4 | G3-designate multibyte 94-set | 94^n字符集用于G3 |
| ESC $ - | 1B 24 2D | G1DM6 | G1-designate multibyte 96-set | 96^n字符集用于G1 |
| ESC $ . | 1B 24 2E | G2DM6 | G2-designate multibyte 96-set | 96^n字符集用于G2 |
| ESC $ / | 1B 24 2F | G3DM6 | G3-designate multibyte 96-set | 96^n字符集用于G3 |
| ESC $ @/B | 1B 24 40/42 | 切换至JIS X 0208 | ||
| ESC $ A | 1B 24 41 | 切换至GB 2312 |
因此,我们可以知道‘0x0F21’表示对应字符集中G0的第一个字符,相应的,‘0x0E21’表示G1的第一个字符。再看相对复杂一点的例子,如,完整代表‘啊’的字节为‘0x1B 0x24 0x29 0x41 0x0E 0x30 0x21’,其中,前4个字节从上表可查知是‘ESC $ ) A’,表示切换到GB2312,接下来的是‘S0’,是指示使用G1,因此‘啊’在GB2312中的码点‘16-01’各自加0x20,形成最后2个字节‘0x3021’。
GB2312
‘GB2312’,以及之后的扩展字符集,‘GBK’ 和 ‘GB18030’,都是中国官方定义的标准字符集,‘GB’就是国家标准的拼音首字母缩写。
GB遵循ISO/IEC 2022标准,将所有字符放在94x94的格子中,也被称为区位码。将字符所在的区块称为区,区中的位置称为位。比如,‘啊’是第16区的第一个字符,因此对应的码点就是16-01。
GB2312总共包含7445个字符,并将之分为3级。
| 区 | 总数 | 描述 |
|---|---|---|
| 1~9 | 682 | 包括了标点符号和其余的特殊字符;还有平假名,片假名,希腊字符,斯拉夫字符,拼音等。 |
| 16~55 | 3755 | 使用频率最高的中文一级字符,以拼音排序。 |
| 56~87 | 3008 | 使用频率次高的中文二级字符,以部首笔画排序。 |
让我们来看一些相关的编码系统。
-
根据ISO 2022说明,编码系统可以用1字节表示ASCII,2字节表示其余字符。因而我们可以用区位码各自加32得到相关的ISO 2022码点,比如,‘0x3021’是‘啊’的码点,当然,我们之前已经知道转义序列,完整的字节应该是‘0x1B 0x24 0x29 0x41 0x0E 0x30 0x21’。
-
之前我们也提到过,‘EUC-CN’,中文扩展Unix代码(Extend Unix code for CN),是‘GB2312’最流行的编码系统,也被称为‘cp1383’。也是一种变长编码系统,GL和ASCII相同,其余的用2个字节表示。
不同于标准的ISO 2022标准,EUC-CN并没有采用转义序列的方式来区分G0,G1等,而是将ISO 2022码的多余的那个比特置为1作为区分,等同于GB2312码点对应字节再加’0xA0’。比如,‘啊(16-01)’对应的编码字节是‘0xB0A1’。
在上文我们已经知道区位码的最大值是‘87-94’,因此我们可以推算出第一个字节的范围是‘0xA1~0xF7’,以及第二个字节是‘0xA1~0xFE’。
字节 字节 1 字节 2 1 0x21~0x7E 2 0xA1~0xF7 0xA1~0xFE -
早期,Windows为GB2312实现了936代码页,后来又用于GBK。因此‘cp936’也是GB2312和GBK的编码,和‘EUC-CN’的实现方式相同。附带说一句,这里的代码页是由微软定义的,和对应于ASCII的IBM定义的‘cp367’不是同一套。
GBK
GBK是GB2312的扩展,总共包含21886个字符,除了GB2312中已有的字符外,还包括了中文繁体以及其它一些未表示的中文字符。分为5个层级,级别1,级别2和GB2312相同,级别3到5占用了GB2312未使用的字节范围。详见下表(采用EUC-CN编码)。
| 级别 | 字节 1 | 字节 2 |
|---|---|---|
| GBK/1 | 0xA1~0xA9 | 0xA1~0xFE |
| GBK/2 | 0xB0~0xF7 | 0xA1~0xFE |
| GBK/3 | 0x81~0xA0 | 0x40~0xFE except 0x7F |
| GBK/4 | 0xAA~0xFE | 0x40~0xA0 except 0x7F |
| GBK/5 | 0xA8~0xA9 | 0x40~0xA0 except 0x7F |
CNS 11643
CNS 11643,中国国家标准11643(Chinese National Standard 11643),也是官方标准,不过值得注意的是,这里的国家是中华民国(Republic of China),而不是PRC(中华人民共和国),是在台湾使用的标准,事实上,Big5使用更广泛。
一共有16个平面,平面12到15是保留给用户自定义的字符,最大可支持141376个字符。对应的EUC编码是 ‘EUC-TW’。
| 字节 | 字节 1 | 字节 2 | 字节 3 | 字节 4 |
|---|---|---|---|---|
| 1 | 0x21~0x7E | |||
| 2 | 0xA1~0xFE | 0xA1~0xFE | ||
| 4 | 0x8E | 0xA1~0xB0 | 0xA1~0xFE | 0xA1~0xFE |
Big5
Big5既是一个繁体中文字符集,也是相应的编码系统,主要使用于台湾,香港和澳门等地,在Windows对应 ‘cp950’。
Big5和ISO 2022标准并不兼容,第一个字节范围是‘0x81~0xFE’,第二个字节范围‘0x40~0x7E,0xA1~0xFE’,详细的结构如下。
| 字节 1 | 字节 2 | 描述 |
|---|---|---|
| 0x81~0xA0 | 0x40~0x7E, 0xA1~0xFE | 保留作为用户自定义字符 |
| 0xA1~0xA3 | 0x40~0x7E, 0xA1~0xBF | 图形字符 |
| 0xA3~0xA3 | 0xC0~0xFE | 保留,不用于用户自定义 |
| 0xA4~0xC6 | 0x40~0x7E | 最常使用字符,以部首笔画排序 |
| 0xC6~0xC8 | 0xA1~0xFE | 保留作为用户自定义字符 |
| 0xC9~0xF9 | 0x40~0x7E, 0xA1~0xD5 | 次常使用字符,以部首笔画排序 |
| 0xF9~0xFE | 0xD6~0xFE | 保留作为用户自定义字符 |
严格来说,这是一个定长双字节字符系统(DBCS),需要使用其余的诸如ASCII这样的SBCS来表示英文字符等,所以一般我们也可以像其余CJK编码系统一样把它当做变长的字符系统。
因为第二字节的范围覆盖了SBCS的范围‘0x20~0x7F’,有时会导致一些解析上的问题,例如,‘功(0xA55C)’的第二个字节和‘\(0x5C)’的值相同,而‘\’常用来作为转义字符。这类问题只发生在Big5和Shift-JIS,ISO 2022和EUC系列的编码则不会有类似问题。
JIS X
‘JIS X 0208’,日本工业标准(Japanese Industrial Standards),和GB2312很相似,也是把所有字符分为94x94的区点(Kuten)。如同GB2312中的‘啊’,JIS X中的码点16-01代表‘亜’。事实上,韩国的 ‘KS X’ 也是采用同样的结构。如同GB2312一样,JIS X 0208也有新的扩展字符集,‘JIS X 0212’ 和 ‘JIS X 0213’。
JIS X 0208一共包括6879个图形字符,其中6355个汉字和524个非汉字。不同于GB2312,JIS X并不是完全兼容ASCII。
| 区 | 总数 | 描述 |
|---|---|---|
| 1~8 | 524 | 特殊字符,数字,平假名,片假名,希腊和斯拉夫字符等。 |
| 16~47 | 2965 | 级别1汉字。 |
| 48~84 | 3390 | 级别2汉字。 |
相关的编码系统。
-
之前介绍过,为了兼容ASCII,ISO 2022需要对多字节字符的每个字节加‘0x20’,JIS X 0208对应的转义序列是‘ESC $ B’,因此‘亜(16-01)’的编码字节是‘0x1B 0x24 0x42 0x30 0x21’。
-
日文扩展Unix代码(Extend Unix code for JP),在日本,这是Unix系统中最常用的编码系统,如同Shift-JIS对于Windows。与‘EUC-CN’不同的是,半角字符,使用‘0x8E’作为第一个字节,而‘0xA1~0xDF’作为第二个字节范围,比如,‘0x8EA7’代表‘ァ’。
同样的理由,我们可以得到第一个字节的范围是‘0xA1~0xF4’,第二个是‘0xA1~0xFE’。
需要注意的是,如果字符是来自于JIS X 0212(C3),而不是JIS X 0208的,需要相应的3个字节来表示,首字节‘0x8F’,其余的两个字节范围是‘0xA1~0xFE’。
字节 字节 1 字节 2 字节 3 1 0x00~0x7F 2 0x8E 0xA1~0xDF 2 0xA1~0xF4 0xA1~0xFE 3 0x8F 0xA1~0xFE 0xA1~0xFE -
转换日本工业标准(Shift Japanese Industrial Standards),在Windows中对应于 ‘cp932’。这也是个变长编码系统,对于单字节,采用JIS X 0201标准,占用‘0x00~0x7F,0xAE~0xDF’的字节范围;对于2字节,则采用下列的公式进行计算。
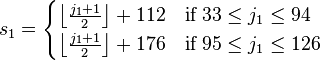
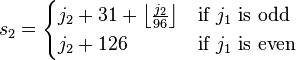
‘s1s2’是指字节数值,而‘j1j2’等于码点 + 32。
s1 = floor((j1 + 1) / 2) + (j1 < 95 ? 112 : 176) s2 = j1 % 2 ? j2 + 31 + floor(j2 / 96) : j2 + 126例如,‘亜(1601)’,从j1 = 48,j2 = 33我们可以计算出s1 = 136,s2 = 159,因此对应的字节应该是‘0x889F’。
从JIS X 0208(01~84)的区范围和上面的公式,我们可以计算出相应的字节范围,第一个字节‘0x81~0x9F,0xE0~0xEA’,后一个字节‘0x40~0x7E,0x80~0xFC’。
‘JIS X 0212’ 是基于JIS X 0208在辅助平面的扩展,包括了6067个字符,基本已废弃。之后的 ‘JIS X 0213’,一共包含11233个字符,分为2个平面,平面1是‘JIS X 0208’的超集,平面2则是‘JIS X 0212’的修订版。
UCS
全世界有N多不同的语言,每个语言又有这么多不同的字符集,导致在不同的系统之间传输数据变得困难。终于,有人站出来说他要做统一的工作,要把所有的字符都包括在一个超级大的集合中,通用字符集(Universal Character Set),简称为UCS。两个不同的组织都做了这个工作,并且发布了各自的标准,Unicode称为 ‘Unicode’,ISO称为 ‘ISO 10646’,两者互相兼容,Unicode更为好记,因此更广为人知。有时,当谈论到UCS或Unicode时,指的是同一回事。
UCS有16个平面,起始的256个字符和ISO-8859-1一致,第一个平面称为‘基本多语种平面(Basic Multilingual Plane)’,是一些编码系统默认的映射集合。
| 平面 | 码点 | 描述 |
|---|---|---|
| 0 | U+0000~U+FFFF | BMP,基本多语种平面 |
| U+D800~U+DBFF | 高代理(High-surrogate)码点,共1024 | |
| U+DC00~U+DFFF | 低代理(Low-surrogate)码点,共1024 | |
| U+E000~U+F8FF | 私有区域,共6400字符 | |
| U+FDD0~U+FDEF | 非字符(noncharacters)区,从不使用 | |
| 1 | U+10000~U+13FFF, U+16000~U+16FFF, U+1B000~U+1BFFF, U+1D000~U+1FFFF | SMP, 辅助多语种平面 |
| 2 | U+20000~U+2BFFF, U+2F000~U+2FFFF | SIP, 辅助表意平面 |
| 3~13 | U+30000~U+DFFFF | |
| 14 | U+E0000~U+EFFFF | SSP, 辅助专用平面 |
| 15~16 | U+F0000~U+10FFFF | S PUA, 辅助私有区域 |
* 所有以‘FFFE/FFFF’结尾的码点都是非字符(noncharacters),比如‘U+FFFE’和‘U+10FFFF’。
相应的一些编码系统。
-
UTF,全称‘统一传输格式(Unicode Transformation Format)’,是Unicode定义的编码系统。
由于作为默认的XML和HTML的编码,UTF-8成为了最流行的编码系统。
码点 字节 1 字节 2 字节 3 字节 4 描述 U+0000~U+007F 0xxxxxxx 与ASCII相同 0x00~0x7F U+0080~U+07FF 110xxxxx 10xxxxxx 绝大多数拉丁字符 0xC2~0xDF 0x80~0xBF U+0800~U+FFFF 1110xxxx 10xxxxxx 10xxxxxx BMP,包括最常用的CJK字符 0xE0~0xEF 0x80~0xBF 0x80~0xBF U+10000~U+10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 辅助平面 0xF0~0xF4 0x80~0xBF 0x80~0xBF 0x80~0xBF -
UCS-2是用和BMP码点相同的固定2个字节来表示字符的编码系统,已被‘UTF-16’代替。
-
UTF-16是Unicode的变长编码。如同前身的编码系统‘UCS-2’,对于BMP,采用和码点相同的字节表示,比如,‘啊(U+554A)’就直接用‘0x554A’表示;对于其它的辅助平面,则需要20个比特来表示码点,前10比特(0x0000~0x03FF)加‘0xD800’得到高代理字节,然后后10比特加上‘0xDC00’得到低代理字节。
lead surrogate = x >> 10 & 0x3FF + 0xD800 trail surrogate = x & 0x3FF + 0xDC00
BOM
字节序标记(Byte Order Mark),在实际字符开始附加的一个Unicode字符,用来指明字节序,有时也用来代表所用编码。
UTF-16使用‘0xFEFF’作为BOM,如果在Unicode文本的开头检测到相反顺序的‘0xFFFE’,则表明是采用小头排序(little-endian),这也是为什么在Unicode中‘U+FFFE’被定义为非字符的原因。
UTF-8使用‘U+FEFF’的UTF-8格式,‘0xEF 0xBB 0xBF’作为BOM,因为UTF-8不关心字节序,因此该字节序标记通常出现在文本开头用来检测是否是UTF-8编码的文本。
其它
还有一些不同的编码方式用于传输或其它领域。
ANSI
ANSI,美国国家标准学会(American National Standards Institute)。微软定义的第一个代码页‘cp1252’,就是基于ANSI的‘ISO-8859-1’的一个草案,后来Windows的代码页就都被称为ANSI代码页。
如果在Windows中选择用‘ANSI’编码存储文件,等价于使用系统语言默认的编码存储,英文的话就是‘ASCII’,中文是‘GB2312 / GBK’,日文则是‘JIS’。
Base64
这是一种用64个ASCII字符来表示二进制数据的编码方式,使用固定的‘A-Za-z0-9’这62个字符,以及其它2个在不同变体中可能不同的可打印字符。我们经常会在email或图片表示中看到这种编码。
由于Base64总共64个字符,3个字节的数据可以编码为4个Base64字符,如果字符串字节数不能被3整除,则用比特0凑足,最后跟上填充符号来指明在最后的3字节组中包含多少有效字节。
让我们来看一个基于RFC 1421的例子,采用‘+/’作为最后2个表示字符,‘=’作为填充符号。
base64 h ------> aA== | h | | 68 | | 01 10 10 00 | | 01 10 10 00 00 00 | | 26 | 0 | | a | A | base64 hi ------> aGk= | h | i | | 68 | 69 | | 01 10 10 00 01 10 10 01 | | 01 10 10 00 01 10 10 01 00 | | 26 | 6 | 36 | | a | G | k |
‘UTF-7’ 是Base64的一个变种,将UTF-16编码的字节用Base64方式再编码,可以使用‘+/v8 | +/v9 | +/v+ | +/v/’作为BOM,所以有时候UTF-7编码的字符串可以绕过诸如htmlentities这种常规的脚本标签转义检查。
Quoted-printable
这是一种将除ASCII字符以外的所有字节都转为以‘=’为前缀的2个十六进制字符的编码方式,例如,GB2312中‘啊’的字节为‘0xB0A1’,转换为QP编码就是‘=B0=A1’。‘=’字符本身编码为‘=3D’。
下面是一封简单邮件的源码,标题和内容都是‘你好,世界’,可以看到标题里用‘=?utf-8?B?’表示采用了UTF-8的Base64编码,内容则是使用QP编码。
Subject: =?utf-8?B?5L2g5aW977yM5LiW55WM?=
Content-Transfer-Encoding: quoted-printable
Content-Type: TEXT/PLAIN; charset=utf-8
=E4=BD=A0=E5=A5=BD=EF=BC=8C=E4=B8=96=E7=95=8C
类似的还有用于URL的 ‘百分号编码’。
综述
下面这个表格总结了上文涉及到的所有编码的字节范围及BOM。一般来说,编码检测工具会首先查看BOM或转义序列来确定使用的编码,这是最简便的一种方式;不行就根据对应的字节范围一一进行排除;如果还不能得出结果,则根据编码的词频比对来推测出最接近的编码。
| 编码 | 字节 1 | 字节 2 | 字节 3 | 字节 4 | BOM / 转义序列 |
|---|---|---|---|---|---|
| ASCII | 0x00~0x7F | ||||
| ISO 8859-* | 0x00~0xFF | ||||
| ISO 2022-CN | 0x00~0x7F | ||||
| 0x21~0x7E | 0x21~0x7E | 0x1B 0x24 [0x29] 0x41 | |||
| ISO 2022-JP | 0x00~0x7F | ||||
| 0x21~0x7E | 0x21~0x7E | 0x1B 0x24 0x42 | |||
| EUC-CN | 0x00~0x7F | ||||
| 0xA1~0xF7 | 0xA1~0xFE | ||||
| EUC-TW | 0x00~0x7F | ||||
| 0xA1~0xFE | 0xA1~0xFE | ||||
| 0x8E | 0xA1~0xB0 | 0xA1~0xFE | 0xA1~0xFE | ||
| EUC-JP | 0x00~0x7F | ||||
| 0x8E | 0xA1~0xDF | ||||
| 0xA1~0xF4 | 0xA1~0xFE | ||||
| 0x8F | 0xA1~0xFE | 0xA1~0xFE | |||
| Big5 | 0x00~0x7F | ||||
| 0xB1~0xA0 | 0x40~0x7E, 0xA1~0xFE | ||||
| 0xA1~0xA3 | 0x40~0x7E, 0xA1~0xBF | ||||
| 0xA3~0xA3 | 0xC0~0xFE | ||||
| 0xA4~0xC6 | 0x40~0x7E | ||||
| 0xC6~0xC8 | 0xA1~0xFE | ||||
| 0xC9~0xF9 | 0x40~0x7E, 0xA1~0xD5 | ||||
| 0xF9~0xFE | 0xD6~0xFE | ||||
| Shift-JIS | 0x00~0x7F, 0xA1~0xDF | ||||
| 0x81~0x9F, 0xE0~0xEA | 0x40~0x7E, 0x80~0xFC | ||||
| UTF-8 | 0x00~0x7F | 0xEF 0xBB 0xBF | |||
| 0xC2~0xDF | 0x80~0xBF | ||||
| 0xE0~0xEF | 0x80~0xBF | 0x80~0xBF | |||
| 0xF0~0xF4 | 0x80~0xBF | 0x80~0xBF | 0x80~0xBF | ||
| UCS-2 | 0x00~0xFF | 0x00~0xFF | |||
| UTF-16 | 0x00~0x7F | 0xFF 0xFE / 0xFE 0xFF | |||
| 0x00~0xFF | 0x00~0xFF |
非常感谢ashtuchkin的工作, 可以访问这个网址看到不同编码系统对应的详细表格。
这里是一个用于转换不同编码的小工具。