Character encoding
http://nozer0.github.io/en/technology/system/character-encoding/Last time, we talk about numbers in computer, and we will take a look how characters stored in computer this time.
Introduce
Here are some terminologies in this article, such as ‘character set’, ‘character encoding system’, ‘QuWei code’ and ‘code point’, we can have an overall concept from the diagram below first, and simple explanations for each will be referred next.
CharSet Computer
+-----------+ Encoding
| a, b, ... | encode +-----------------+
| | | | | ----------> | 0x61, 0x62, ... |
code point -->| 97 98 ... | +-----------------+
+-----------+
First, let us check the concepts of Character set and Encoding. Always, people talk these two interchangeably, but sometimes, they have their own meanings for each other.
-
Character set, or ‘CharSet’, is a set of characters, like all characters used in one language. And the number value of character in one character set is called code point.
-
And character encoding system, is a way to map character set into something serializable like bit patterns, numbers, etc. It doesn’t appear in computers only, we can find it frequently in normal life. For example, when we get a dictionary, it includes one or more encoding ways to help us find the character quickly, or when we send a mail, we need to write the zip code of receiver, which is exactly an encoding way of blocks.
For most situations in Computer Science, these 2 things are same, like ‘ASCII’, ‘ISO8859’; sometimes are not, for example, ‘EUC-CN’ is an encoding way of character set ‘GB2312’.
SBCS
Single-byte character system, we can know from name that these character system only need 7 or 8 bits to represent characters, in other words, maximum 128 or 256 characters in these systems.
We will introduce the three of them, ‘ASCII’ and ‘ISO 8859’, both are most popular worldwide, and the last special one ‘JIS X 0201’ for Japanese.
ASCII
‘American Standard Code for Information Interchange’ system, also AKA ‘ISO646-US’ or ‘cp367’ from IBM. For most people, it should be the earliest encoding bring in.
ASCII bases on the English alphabet, includes 96 printable characters(26 characters, 0-9 numbers, some basic punctuation symbols and blank space), 32 control codes, 128 characters totally, which can be represented by 7 bits. Only 1 byte is enough to represent almost everything for English people, and here is one more bit left which can be used for parity check, simple and small, isn’t it?
Full ASCII table.
| Hex | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL (Null character) | DLE (Data Link Escape) | SP | 0 | @ | P | ` | p |
| 1 | SOH (Start of Header) | DC1 (Device Control 1) | ! | 1 | A | Q | a | q |
| 2 | STX (Start of Text) | DC2 (Device Control 2) | ” | 2 | B | R | b | r |
| 3 | ETX (End of Text) | DC3 (Device Control 3) | # | 3 | C | S | c | s |
| 4 | EOT (End of Transmission) | DC4 (Device Control 4) | $ | 4 | D | T | d | t |
| 5 | ENQ (Enquiry) | NAK (Negative Acknowledgment) | % | 5 | E | U | e | u |
| 6 | ACK (Acknowledgment) | SYN (Synchronous idle) | & | 6 | F | V | f | v |
| 7 | BEL (Bell) | ETB (End of Transmission Block) | ’ | 7 | G | W | g | w |
| 8 | BS (Backspace, ‘\b’) | CAN (Cancel) | ( | 8 | H | X | h | x |
| 9 | HT (Horizontal Tab, ‘\t’) | EM (End of Medium) | ) | 9 | I | Y | i | y |
| A | LF (Line feed, ‘\n’) | SUB (Substitute) | * | : | J | Z | j | z |
| B | VT (Vertical Tab, ‘\v’) | ESC (Escape) | + | ; | K | [ | k | { |
| C | FF (Form feed, ‘\f’) | FS (File Separator) | , | < | L | \ | l | | |
| D | CR (Carriage return, ‘\r’) | GS (Group Separator) | - | = | M | ] | m | } |
| E | SO (Shift Out) | RS (Record Separator) | . | > | N | ^ | n | ~ |
| F | SI (Shift In) | US (Unit Separator) | / | ? | O | _ | o | DEL |
ISO/IEC 8859
ASCII is good enough for US, however, for other Latin language countries, they need more additional symbols to be represented, so the extended encoding system using one more bit than ASCII was defined. And it has several parts for different locales, such as ‘ISO-8859-1’ for Western European, ‘ISO-8859-2’ for Central European, etc.
All ‘ISO-8859’ variable parts are use 8 bits, and the beginning 128 characters are the same as ASCII, this is called ASCII compliant character set. Actually, ‘ISO 8859’ only defines the bytes range ‘0xA0~0xFF’, and ‘ISO 6429’ defines the C0 and C1 control characters(0x00~0x1F, 0x80~0x9F), more accurately, ISO-8859 = ASCII + ISO 6429 + ISO 8859, be aware of the dash symbol ‘-‘.
JIS X 0201
This is the single byte character set early used in Japan, different than normal ASCII, it replaces ‘' to ‘¥’ on ‘0x5C’, that’s why we always see such path ‘C:¥windows¥system’ in Japanese Environment, and also ‘~’ to ‘‾’ on ‘0x7E’. And the bytes of ‘0xA1~0xDF’ is used for half-width katakana.
MBCS
Multi-byte character system, contrast to SBCS, which is mainly used for Latin language family countries, MBCS is defined for the other countries who have much more characters to be represented, like China or Japan. Obviously, only 1 byte is not enough.
ISO/IEC 2022
ISO 2022 is neither a character set nor encoding system, it’s a standard or code extension technique to use single encoding system to represent multiple character sets. It specifies that 1 byte (accurately 7 bits) to represent 94 printable characters, to be consistent with ASCII, using ‘0x21~0x7E’; 2 bytes, 94 rows x 94 columns = 8836 characters, for most language, this is enough; specially, 3 bytes, 94 planes x 8836 = 830584 characters.
In addition, ISO 2022 specifies 2-layer mapping between character codes and display characters, here are 4 working sets designated, named from G0 to G3, it should detect which working set is used now, and then get the correct character in the set based on byte values. This is the default situations.
| Set | Range | Name |
|---|---|---|
| CL | 0x00~0x1F | control codes on left, default as C0 |
| GL | 0x20~0x7F | graph characters on left, default as G0 |
| CL | 0x80~0x9F | default as C1 |
| GR | 0xA0~0xFF | default as G1 |
Moreover, ISO 2022 can use ‘Escape sequences’ to indicate which working set should be used for next bytes.
| Code | Hex | Abbr | Name | Effect |
|---|---|---|---|---|
| SI | 0F | LS0 | Shift In / Locking shift zero | GL encodes G0 from now on |
| SO | 0E | LS1 | Shift Out / Locking shift one | GL encodes G1 from now on |
| ESC n | 1B 6E | LS2 | Locking shift two | GL encodes G2 from now on |
| ESC o | 1B 6F | LS3 | Locking shift three | GL encodes G3 from now on |
| ESC N | 8E/1B 4E | SS2 | Single shift two | GL encodes G2 for next character only |
| ESC O | 8F/1B 4F | SS3 | Single shift three | GL encodes G3 for next character only |
| ESC ~ | 1B 7E | LS1R | Locking shift one right | GR encodes G1 from now on |
| ESC } | 1B 7D | LS2R | Locking shift two right | GR encodes G2 from now on |
| ESC | | 1B 7C | LS3R | Locking shift three right | GR encodes G3 from now on |
| ESC ! | 1B 21 | CZD | C0-designate | C0 control character set to be used |
| ESC “ | 1B 22 | C1D | C1-designate | C1 control character set to be used |
| ESC % | 1B 25 | DOCS | Designate other coding system | 8-bit code; use ESC % @ to return to ISO 2022 |
| ESC % / | 1B 25 2F | DOCS | Designate other coding system | 8-bit code; there is no standard way to return |
| ESC ( | 1B 28 | GZD4 | G0-designate 94-set | 94-character set to be used for G0 |
| ESC ( B | 1B 28 42 | switch to ASCII | ||
| ESC ( I/J | 1B 28 49/4A | switch to JIX X 0201 | ||
| ESC ) | 1B 29 | G1D4 | G1-designate 94-set | 94-character set to be used for G1 |
| ESC * | 1B 2A | G2D4 | G2-designate 94-set | 94-character set to be used for G2 |
| ESC + | 1B 2B | G3D4 | G3-designate 94-set | 94-character set to be used for G3 |
| ESC - | 1B 2D | G1D6 | G1-designate 96-set | 96-character set to be used for G1 |
| ESC . | 1B 2E | G2D6 | G2-designate 96-set | 96-character set to be used for G2 |
| ESC . A | 1B 2E 41 | switch to ISO 8859-1 | ||
| ESC . F | 1B 2E 46 | switch to ISO 8859-7 | ||
| ESC / | 1B 2F | G3D6 | G3-designate 96-set | 96-character set to be used for G3 |
| ESC $ ( | 1B 24 28 | GZDM4 | G0-designate multibyte 94-set | 94^n-character set to be used for G0 |
| ESC $ ( C | 1B 24 44 | switch to KS X 1001 | ||
| ESC $ ( D | 1B 24 44 | switch to JIS X 0212 | ||
| ESC $ ( O..Q | 1B 24 4F..51 | switch to JIS X 0213 | ||
| ESC $ ) | 1B 24 29 | G1DM4 | G1-designate multibyte 94-set | 94^n-character set to be used for G1 |
| ESC $ ) A | 1B 24 29 41 | switch to GB 2312 | ||
| ESC $ ) C | 1B 24 29 43 | switch to KS X 1001 | ||
| ESC $ * | 1B 24 2A | G2DM4 | G2-designate multibyte 94-set | 94^n-character set to be used for G2 |
| ESC $ + | 1B 24 2B | G3DM4 | G3-designate multibyte 94-set | 94^n-character set to be used for G3 |
| ESC $ - | 1B 24 2D | G1DM6 | G1-designate multibyte 96-set | 96^n-character set to be used for G1 |
| ESC $ . | 1B 24 2E | G2DM6 | G2-designate multibyte 96-set | 96^n-character set to be used for G2 |
| ESC $ / | 1B 24 2F | G3DM6 | G3-designate multibyte 96-set | 96^n-character set to be used for G3 |
| ESC $ @/B | 1B 24 40/42 | switch to JIS X 0208 | ||
| ESC $ A | 1B 24 41 | switch to GB 2312 |
So that we can know byte ‘0x0F21’ represents the first character in G0 of regarding character set, correspondingly, ‘0x0E21’ represents the first character in G1. For instance, the bytes of ‘啊’ are ‘0x1B 0x24 0x29 0x41 0x0E 0x30 0x21’, the first 4 bytes ‘ESC $ ) A’ indicates to use ‘GB2312’, and ‘S0’ denotes G1, the last 2 bytes ‘0x3021’ points to ‘16-01’ + 0x20(G1), which is the code point of ‘啊’ in GB2312.
GB2312
‘GB2312’, and the later extend character sets, ‘GBK’, and ‘GB18030’, are all the official character sets of China. ‘GB’ abbreviates ‘GuoBiao(国家标准)’, which means national standard.
GB arranges characters into 94x94 grid, which is also called QuWei(区位) code, following ISO/IEC 2022 standard. And it calls the character zone number as ‘Qu(区)’, the position within zone as ‘Wei(位)’. For example, ‘啊’ is the first character of 16th Qu, so that its code point is 16-01.
GB2312 includes totally 7445 characters, and groups them into 3 levels.
| Zone | Num | Description |
|---|---|---|
| 1~9 | 682 | Comprising punctuation and other special characters; also Hiragana, Katakana, Greek, Cyrillic, Pinyin. |
| 16~55 | 3755 | The first plane for Chinese characters, arranged according to Pinyin. |
| 56~87 | 3008 | The second plane for Chinese characters, arranged according to radical and strokes. |
Let us see several regarding encoding systems.
-
According to the ISO 2022 specification, the encoding system can use 1 byte to represent ASCII, and 2 bytes for others. We can get the related ISO 2022 codes by adding 32 to the QuWei code, i.e, ‘啊’ is ‘0x3021’, of course, we already know it has prefix escape sequence codes, the full bytes are ‘0x1B 0x24 0x29 0x41 0x0E 0x30 0x21’.
-
As we mentioned above, ‘EUC-CN’, ‘Extend Unix code for CN’, is the most popular encoding system of ‘GB2312’, also referred to as ‘cp1383’. It is also variable-width encoding system, GL plane is the same as ASCII, and 2 bytes for others.
Unlike native ISO 2022 codes, it doesn’t use the escape sequence codes, to avoid the confusion with normal ASCII characters, it sets the first bit to 1 based on the ISO 2022 code, what is equal to add ‘0xA0’ to the native GB2312 code point for each byte. For example, ‘啊(16-01)’, and the encoding bytes value is ‘0xB0A1’.
And we already know from above, that the maximum QuWei code is ‘87-94’, so that we can get the first byte value range is ‘0xA1~0xF7’, and second byte is ‘0xA1~0xFE’.
Bytes Byte 1 Byte 2 1 0x21~0x7E 2 0xA1~0xF7 0xA1~0xFE -
In early time, Windows implements code page 936 for GB2312, and GBK later. So ‘cp936’ is also the encoding of GB2312 and GBK, it is the same implementation as ‘EUC-CN’. FYI, here the code pages are the ones defined by Microsoft, not the ‘cp367’ for ASCII, which is defined by IBM.
GBK
GBK is the extension of GB2312, 21886 characters totally, in addition to the ones included in GB2312, traditional Chinese characters and other unrepresentable Chinese characters are also included. It has 5 levels, the level 1 and 2 is the same as GB2312, and level 3~5 take the byte range unused in GB2312. Check the table for details.
| Level | Byte 1 | Byte 2 |
|---|---|---|
| GBK/1 | 0xA1~0xA9 | 0xA1~0xFE |
| GBK/2 | 0xB0~0xF7 | 0xA1~0xFE |
| GBK/3 | 0x81~0xA0 | 0x40~0xFE except 0x7F |
| GBK/4 | 0xAA~0xFE | 0x40~0xA0 except 0x7F |
| GBK/5 | 0xA8~0xA9 | 0x40~0xA0 except 0x7F |
CNS 11643
CNS 11643, Chinese National Standard 11643, it is the official standard of Republic of China. Please pay attention, it’s Republic of China(中华民国), not PRC(People’s Republic of China), so it’s used in Taiwan, in fact, Big5 is more commonly used.
It contains 16 planes, from plane 12 to 15 are designated for user-defined characters, 141376 characters maximumly. The relevant EUC form encoding is ‘EUC-TW’.
| Bytes | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
| 1 | 0x21~0x7E | |||
| 2 | 0xA1~0xFE | 0xA1~0xFE | ||
| 4 | 0x8E | 0xA1~0xB0 | 0xA1~0xFE | 0xA1~0xFE |
Big5
Big5 is both a traditional Chinese character set and the relevant encoding system, which is popular used in Taiwan, HongKong and Macau, also referred as ‘cp950’ in Windows.
It does not conform the ISO 2022 standard, and with the first byte range ‘0x81~0xFE’, second byte range ‘0x40~0x7E, 0xA1~0xFE’, the detail structure is.
| Byte 1 | Byte 2 | Description |
|---|---|---|
| 0x81~0xA0 | 0x40~0x7E, 0xA1~0xFE | Reserved for user-defined characters |
| 0xA1~0xA3 | 0x40~0x7E, 0xA1~0xBF | Graphical characters |
| 0xA3~0xA3 | 0xC0~0xFE | Reserved, not for user-defined characters |
| 0xA4~0xC6 | 0x40~0x7E | Frequently used characters, arranged according to radical and strokes |
| 0xC6~0xC8 | 0xA1~0xFE | Reserved for user-defined characters |
| 0xC9~0xF9 | 0x40~0x7E, 0xA1~0xD5 | Less frequently used characters, arranged according to radical and strokes |
| 0xF9~0xFE | 0xD6~0xFE | Reserved for user-defined characters |
Strictly speaking, it is a fixed DBCS, double bytes character system, it needs to use other SBCS like ASCII to represent the ones like English characters, generally, we can take it as variable-width character system like other CJK encoding systems.
And because the byte range of second byte is overlapped with SBCS ‘0x20~0x7F’, it may lead problem sometimes, for example, ‘功(0xA55C)’, the second byte is the same value of ‘\(0x5C)’, which is always used as escape character. This problem only occurs in Big5 and Shift-JIS, and won’t happen in ISO 2022 and EUC compliant encodings.
JIS X
‘JIS X 0208’, Japanese Industrial Standards, it’s very similar like GB2312, groups all characters into 94 row x 94 positions called ‘Kuten(区点)’ code, the same thing called ‘QuWei(区位)’ code in GB. Just like ‘啊’ in GB2312, the code point 16-01 in JIS X points to ‘亜’. Actually, the same structure is employed by Korean with ‘KS X’. As well as GB2312, JIS X 0208 has new extend character sets, ‘JIS X 0212’ and ‘JIS X 0213’.
JIS X 0208 includes 6879 graph characters totally, among it 6355 kanji and 524 hikanji. Unlike GB2312, it’s not fully compliant with ASCII, it uses bytes ‘0xA1~0xDF’ to represent half-width kana.
| Zone | Num | Description |
|---|---|---|
| 1~8 | 524 | Special characters, numbers, Hiragana, Katakana, Greek, Cyrillic, etc. |
| 16~47 | 2965 | The kanji characters of level 1. |
| 48~84 | 3390 | The kanji characters of level 2. |
Here are some regarding encoding systems.
-
As introduced above, to compliant with ASCII, ISO 2022 should add ‘0x20’ on each byte of multiple bytes character, and ‘ESC $ B’ is the escape codes of JIS X 0208, so the bytes for ‘亜(16-01)’ are ‘0x1B 0x24 0x42 0x30 0x21’.
| Bytes | Byte 1 | Byte 2 | Byte 3 |
|:-----:|-----------|-----------|-----------|
| 1 | 0x00~0x7F | | |
| 2 | 0x8E | 0xA1~0xDF | |
| 2 | 0xA1~0xF4 | 0xA1~0xFE | |
| 3 | 0x8F | 0xA1~0xFE | 0xA1~0xFE |
-
Shift Japanese Industrial Standards, or ‘cp932’ in Windows. This encoding is also variable-width, for single byte, it is compatible with JIS X 0201, takes the ‘0x00~0x7F, 0xAE~0xDF’ as byte range; And for 2 bytes, it is not compatible with ISO 2022, instead it uses the formula below.
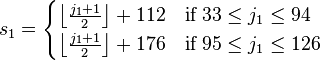
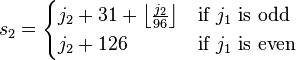
‘s1s2’ are the bytes value, and ‘j1j2’ are (code point + 32).
s1 = floor((j1 + 1) / 2) + (j1 < 95 ? 112 : 176) s2 = j1 % 2 ? j2 + 31 + floor(j2 / 96) : j2 + 126For example, ‘亜(1601)’, j1 = 48, j2 = 33, then we can get s1 = 136, s2 = 159 with previous formula, so the bytes should be ‘0x889F’.
Based on the range of JIS X 0208(01~84) and this formula, we can calculate the first byte range is ‘0x81~0x9F, 0xE0~0xEA’, the second is ‘0x40~0x7E, 0x80~0xFC’.
‘JIS X 0212’ is the extended set of JIS X 0208 for supplementary plane, including 6067 characters totally, effectively dead. And the later one, ‘JIS X 0213’, 11233 characters totally, divided into 2 planes, plane 1 as the superset of ‘JIS X 0208’, and plane 2 as the revised ‘JIS X 0212’.
UCS
There are so many different languages in the world so as to define so many different characters sets, it is difficult to transfer data between different systems. Finally, someone stands up to do the unique work that groups all characters into one super big set, the universal character set, abbreviates ‘UCS’.
Here are 2 organizations publish their own definition at almost same time, Unicode calls it as ‘Unicode’, and ISO calls ‘ISO 10646’, both of them are compatible to each other, but Unicode is easy to remember so as to be more widely known. Sometimes, when saying ‘UCS’ or ‘Unicode’, taken as the same thing.
It has 16 planes, the first one, which is called as ‘BMP’ with the first 256 characters identical to ISO-8859-1, is always the mapping set for some encodings.
| Plane | Code Point | Description |
|---|---|---|
| 0 | U+0000~U+FFFF | BMP, Basic Multilingual Plane |
| U+D800~U+DBFF | High-surrogate codes, 1024 totally | |
| U+DC00~U+DFFF | Low-surrogate codes, 1024 totally | |
| U+E000~U+F8FF | Private use area, 6400 totally | |
| U+FDD0~U+FDEF | Noncharacters, never to be used | |
| 1 | U+10000~U+13FFF, U+16000~U+16FFF, U+1B000~U+1BFFF, U+1D000~U+1FFFF | SMP, Supplementary Multilingual Plane |
| 2 | U+20000~U+2BFFF, U+2F000~U+2FFFF | SIP, Supplementary Ideographic Plane |
| 3~13 | U+30000~U+DFFFF | |
| 14 | U+E0000~U+EFFFF | SSP, Supplementary Special-purpose Plane |
| 15~16 | U+F0000~U+10FFFF | S PUA, Supplementary Private Use Area |
* All codes ending with ‘FFFE/FFFF’ are noncharacters, such as ‘U+FFFE’ and ‘U+10FFFF’.
Several corresponding encoding systems.
-
‘UTF’, Unicode Transformation Format, is the encoding system defined by Unicode.
UTF-8 is the most popular encoding system since it is used by default for XML and HTML.
Code Points Byte 1 Byte 2 Byte 3 Byte 4 Description U+0000~U+007F 0xxxxxxx The same as ASCII 0x00~0x7F U+0080~U+07FF 110xxxxx 10xxxxxx For almost all Latin characters 0xC2~0xDF 0x80~0xBF U+0800~U+FFFF 1110xxxx 10xxxxxx 10xxxxxx BMP, includes frequently used CJK characters 0xE0~0xEF 0x80~0xBF 0x80~0xBF U+10000~U+10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx Supplementary Planes 0xF0~0xF4 0x80~0xBF 0x80~0xBF 0x80~0xBF -
UCS-2 is an encoding using fixed 2 bytes with same code points in BMP to represent characters, substituted by its super system ‘UTF-16’.
-
UTF-16 is also a variable-width encoding for Unicode. Like its former encoding ‘UCS-2’, for BMP, it’s the same byte values as the code points, for instance, ‘啊(U+554A)’ is represented as ‘0x554A’; And for other supplementary planes, which needs 20 bits to represent the code points, it adds ‘0xD800’ to first 10 bits(0x0000~0x03FF) to get the lead surrogate byte, and ‘0xDC00’ to next ten bits to get trail surrogate byte.
lead surrogate = x >> 10 & 0x3FF + 0xD800 trail surrogate = x & 0x3FF + 0xDC00
BOM
Byte Order Mark, a Unicode character preceded the first actual characters, which used to detect the byte order, and also indicates the encoding system sometimes.
UTF-16 uses ‘0xFEFF’ as BOM, if the opposite order byte ‘0xFFFE’ is detected at the first of Unicode text, we can know that the byte order is little-endian, this is also why ‘U+FFFE’ is defined as noncharacter in Unicode.
UTF-8 uses ‘0xEF 0xBB 0xBF’ as BOM instead, which is the corresponding representation of ‘U+FEFF’ in UTF-8, because UTF-8 doesn’t care the byte order, it always use to denote UTF-8 encoding if appears in the beginning of text.
Others
Here are some other encoding ways used for data transmission or other areas.
ANSI
ANSI, American National Standards Institute. The first code page ‘cp1252’ defined by Microsoft, is based on a ANSI draft of ‘ISO-8859-1’, so as to the Windows code pages are also known as ANSI code pages.
If we choose save file with ‘ANSI’, that means we choose the default encoding based on system language, for examples, ‘ASCII’ for EN, ‘GB2312 / GBK’ for CN, ‘JIS’ for JP.
Base64
This is an encoding way to represent binary data with 64 ASCII characters, which uses ‘A-Za-z0-9’ fixed 62 characters, and other 2 printable characters which may be different in each variations. We can always see this encoding in email or images representation.
Since it has 64 characters totally, so that 3 bytes are encoded into 4 Base64 characters, if string bytes number is not divisible by 3, append 0 in bits at the end, and use pad symbol to indicate how many significant byte in last 3 bytes group.
Let us take an example based on RFC 1421, it uses ‘+/’ as last 2 characters, and ‘=’ as pad symbol.
base64 h ------> aA== | h | | 68 | | 01 10 10 00 | | 01 10 10 00 00 00 | | 26 | 0 | | a | A | base64 hi ------> aGk= | h | i | | 68 | 69 | | 01 10 10 00 01 10 10 01 | | 01 10 10 00 01 10 10 01 00 | | 26 | 6 | 36 | | a | G | k |
‘UTF-7’ is a variant of Base64, it encodes the UTF-16 encoding bytes via the way of Base64, and it can use ‘+/v8 | +/v9 | +/v+ | +/v/’ as BOM, so that sometimes UTF-7 encoding strings can jump over the normal ways to check script tags like htmlentities.
Quoted-printable
This is an encoding to change all bytes except printable ASCII characters to 2 hexadecimal characters with ‘=’ as prefix, for instance, the bytes of ‘啊’ in GB2312 are ‘0xB0A1’, changes to the QP encoding way is ‘=B0=A1’. The ‘=’ character itself is represented by ‘=3D’.
This is a simple email source with the same string ‘你好,世界’ for both subject and content, you can see that the subject is use Base64 encoding indicates by ‘?B?’ and content QP encoding.
Subject: =?utf-8?B?5L2g5aW977yM5LiW55WM?=
Content-Transfer-Encoding: quoted-printable
Content-Type: TEXT/PLAIN; charset=utf-8
=E4=BD=A0=E5=A5=BD=EF=BC=8C=E4=B8=96=E7=95=8C
Similar ‘Percent-encoding’ is used for URL.
Review
This is the table as summary including all encodings byte ranges and BOM mentioned above. Basically, character encoding detect tool will check BOM or escape sequence first, this is the most significant and simple way to know the encoding; and then excludes the encodings if out of byte range; if still no result gets, it checks the bytes based on word frequency to infer the most closed encoding.
| Encoding | Byte 1 | Byte 2 | Byte 3 | Byte 4 | BOM / Escape sequence |
|---|---|---|---|---|---|
| ASCII | 0x00~0x7F | ||||
| ISO 8859-* | 0x00~0xFF | ||||
| ISO 2022-CN | 0x00~0x7F | ||||
| 0x21~0x7E | 0x21~0x7E | 0x1B 0x24 [0x29] 0x41 | |||
| ISO 2022-JP | 0x00~0x7F | ||||
| 0x21~0x7E | 0x21~0x7E | 0x1B 0x24 0x42 | |||
| EUC-CN | 0x00~0x7F | ||||
| 0xA1~0xF7 | 0xA1~0xFE | ||||
| EUC-TW | 0x00~0x7F | ||||
| 0xA1~0xFE | 0xA1~0xFE | ||||
| 0x8E | 0xA1~0xB0 | 0xA1~0xFE | 0xA1~0xFE | ||
| EUC-JP | 0x00~0x7F | ||||
| 0x8E | 0xA1~0xDF | ||||
| 0xA1~0xF4 | 0xA1~0xFE | ||||
| 0x8F | 0xA1~0xFE | 0xA1~0xFE | |||
| Big5 | 0x00~0x7F | ||||
| 0xB1~0xA0 | 0x40~0x7E, 0xA1~0xFE | ||||
| 0xA1~0xA3 | 0x40~0x7E, 0xA1~0xBF | ||||
| 0xA3~0xA3 | 0xC0~0xFE | ||||
| 0xA4~0xC6 | 0x40~0x7E | ||||
| 0xC6~0xC8 | 0xA1~0xFE | ||||
| 0xC9~0xF9 | 0x40~0x7E, 0xA1~0xD5 | ||||
| 0xF9~0xFE | 0xD6~0xFE | ||||
| Shift-JIS | 0x00~0x7F, 0xA1~0xDF | ||||
| 0x81~0x9F, 0xE0~0xEA | 0x40~0x7E, 0x80~0xFC | ||||
| UTF-8 | 0x00~0x7F | 0xEF 0xBB 0xBF | |||
| 0xC2~0xDF | 0x80~0xBF | ||||
| 0xE0~0xEF | 0x80~0xBF | 0x80~0xBF | |||
| 0xF0~0xF4 | 0x80~0xBF | 0x80~0xBF | 0x80~0xBF | ||
| UCS-2 | 0x00~0xFF | 0x00~0xFF | |||
| UTF-16 | 0x00~0x7F | 0xFF 0xFE / 0xFE 0xFF | |||
| 0x00~0xFF | 0x00~0xFF |
Thanks so much for the work of ashtuchkin, here are the detail tables for different encoding systems.
Here also has a small tool to convert between different character encodings.